


长文本理解:大型模型面临挑战
在长文本理解领域,所有大型模型均未达标!北京大学和北京通用人工智能研究院联手推出了一项极具挑战性的新基准测试:LooGLE,专门针对大型语言模型(LLMs)的长上下文理解能力进行测试和评估。该数据集不仅可以评估LLMs处理和检索长文本的能力,还可以评估其对文本长程依赖的建模和理解能力。经过评估,这些模型在复杂的长依赖任务中的多信息检索、时间重排序、计算、理解推理能力表现均不尽人意。例如,像Claude3-200k、GPT4-32k、GPT4-8k、GPT3.5-turbo-6k、LlamaIndex这样的商业模型,平均准确率仅为40%。而开源模型的表现更为糟糕,如ChatGLM2-6B、LongLLaMa-3B、RWKV-4-14B-pile、LLaMA-7B-32K的平均准确率仅为10%。目前,该论文已被ACL2024接收。论文的共同第一作者为通研院的李佳琪和王萌萌,通讯作者为通研院研究员郑子隆和北京大学人工智能研究院助理教授张牧涵。
LooGLE基准测试的特点
LooGLE基准测试具有以下特点:首先,它包含了近800个最新收集的超长文档,平均长度近2万字(是现有相似数据集长度的2倍),并从这些文档中重新生成了6千个不同领域和类别的任务/问题用于构建LooGLE。目前尚无其他数据集既能评估LLMs对长文本的处理和记忆能力,又能评估其对文本长程依赖的建模和理解能力。LooGLE的数据集由7个主要的任务类别组成,旨在评估LLMs理解短程和长程依赖内容的能力。团队设计了5种类型的长期依赖任务,包括理解与推理、计算、时间线重新排序、多重信息检索和摘要。通过人工标注精心生成了超过1100对高质量的长依赖问答对,以满足长依赖性要求。这些问答对经过了严格的交叉验证,从而得到了对大型语言模型(LLMs)长依赖能力的精确评估。LooGLE基准数据集仅包含2022年之后发布的文本,尽可能地避免了预训练阶段的数据泄露,考验大模型利用其上下文学习能力来完成任务,而不是依靠记忆事实和知识储备。该基准的文本源自广泛认可的开源文档,包括了arxiv论文、维基百科文章以及电影和电视剧本,涉及学术、历史、体育、政治、艺术、赛事、娱乐等领域。
长依赖任务的分类与要求
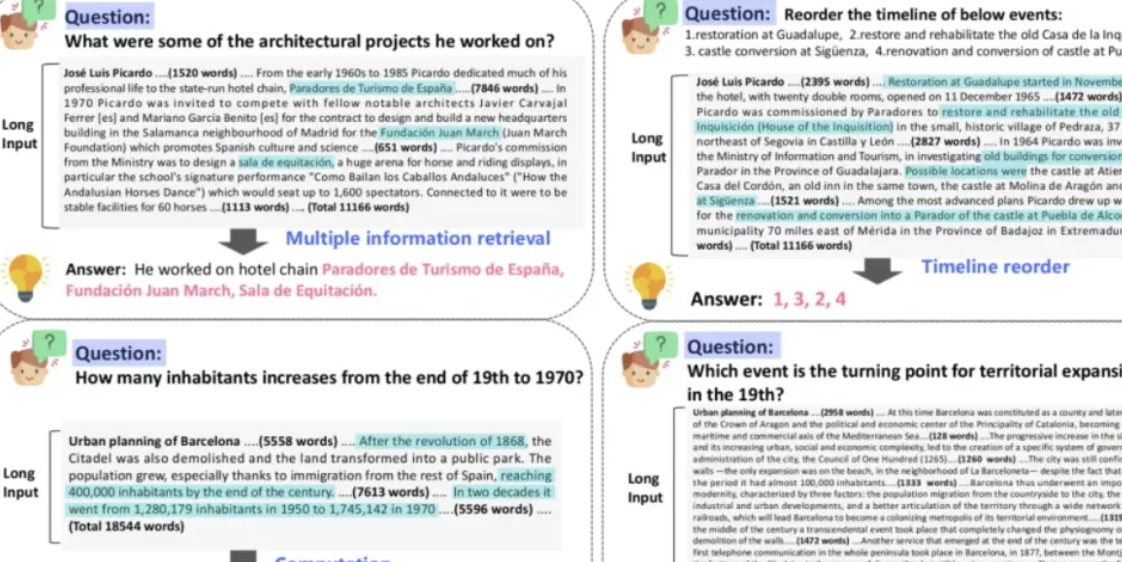
在本研究中,团队组织了近百名标注者手工编制了约1100个真实的长依赖问答对,分为4类长依赖任务:多信息检索、时间重排序、计算、理解推理。多信息检索任务要求从长文本中广泛分布的相关证据或线索中进行检索和提取,然后对这些证据进行汇总,才能得出最终答案。计算任务则需要从广泛的文本中进行多次信息检索提取相关数字,并对这些数字进行计算。时间重排序任务要求模型根据事件在长文本中出现的时间先后顺序将这些事件排列起来。理解推理任务则要求模型利用散落在长上下文中的证据,深入理解问题并推理出答案。
性能评估与关键发现
为了提供更全面和通用的性能评估,LooGLE使用基于语义相似性的度量、GPT4作为判断的度量,以及人类评估作为度量。在LooGLE上对9种最先进的长文本LLMs进行评估后,得出了以下关键发现:商业模型显著优于开源模型;LLMs在短依赖任务方面表现出色,但在更复杂的长依赖任务中均表现不佳;CoT(思维链)只在长上下文理解方面带来了微小的改进;基于检索的技术在短问答方面表现出明显的优势,而通过优化的Transformer架构或位置编码来扩展上下文窗口长度的策略对长上下文理解的提升有限。因此,LooGLE不仅提供了关于长上下文LLMs的系统和全面的评估方案,而且为未来开发增强型模型以实现“真正的长上下文理解”提供了启示。